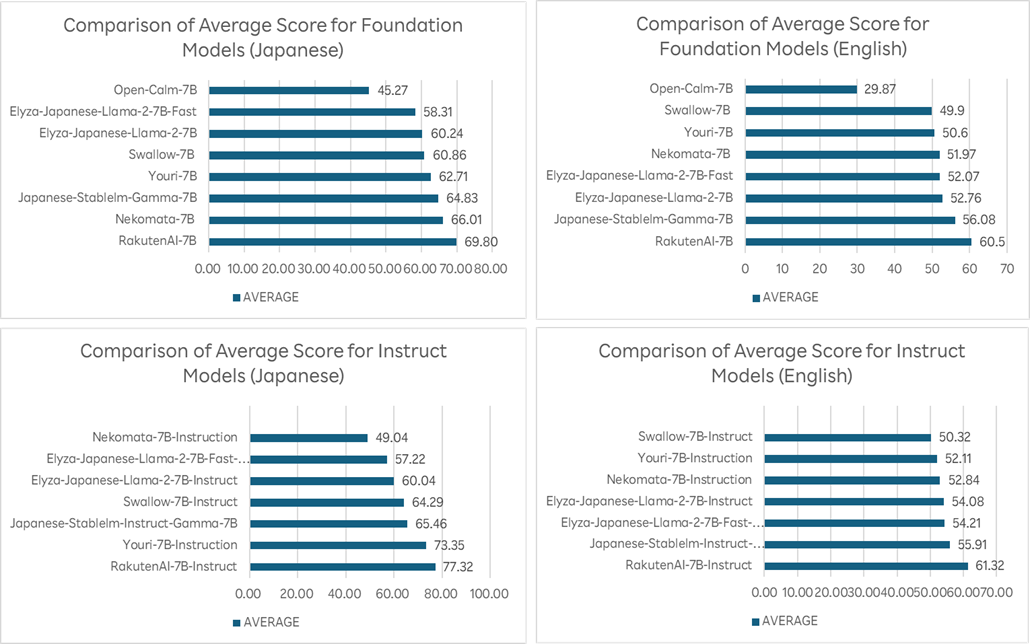
The foundation and instruct models were evaluated on both Japanese and English language performance via LM Evaluation Harness*8, 9. For Japanese, the foundation model achieves an average score of 69.8 points, and the instruct model 77.3 points. For English, the scores are 60.5 for the foundation model and 61.3 for the instruct model. These scores place the models at the top among the open Japanese language LLMs in their respective categories.
“At Rakuten, we want to leverage the best tools to solve our customers’ problems. We have a broad portfolio of tools, including proprietary models and our own data science and machine learning models developed over the years. This enables us to provide the most suitable tool for each use case in terms of cost, quality and performance,” commented Ting Cai, Chief Data Officer of Rakuten Group. “With Rakuten AI 7B, we have reached an important milestone in performance and are excited to share our learnings with the open-source community and accelerate the development of Japanese language LLMs.”
All models can be used commercially for various text generation tasks such as summarizing content, answering questions, general text understanding, and building dialogue systems. In addition, the models can be used as a base for building other models.
Large language models are the core technology powering the Generative AI services that have sparked the recent revolution in AI. Rakuten’s current models have been developed for research purposes, and the company will continue to evaluate various options to deliver the best service to its customers. By developing models in-house, Rakuten can build up its knowledge and expertise in LLMs and create models that are optimized to support the Rakuten Ecosystem. By making the models open, Rakuten aims to contribute to the open source community and promote the further development of Japanese language LLMs.
With breakthroughs in AI triggering transformations across industries, Rakuten has launched its AI-nization initiative, implementing AI in every aspect of its business to drive further growth. Rakuten is committed to making AI a force for good that augments humanity, drives productivity and fosters prosperity.